-
210804_1(데이터분석, R, 자연어처리/텍스트마이닝,통계, 마크다운)BigData 2021. 8. 4. 17:11
#패키지 로드 library(tau) library(dplyr) library(hash) library(rJava) #library(hask) library(vctrs) library(Sejong) library(RSQLite) library(KoNLP) library(stringr) useNIADic() ########################### 국정원 트윗 분석 # 1. 로드 twitter <- read.csv("twitter.csv", header = T, stringsAsFactors = F, fileEncoding = "UTF-8") # 2. 검토 head(twitter) # 컬럼이 한글로 되어있다. # 자료크기 측정 dim(twitter) # [1] 3743 5 # 5개 컬럼 # 전체 데이터형 검사 str(twitter) # 'data.frame': 3743 obs. of 5 variables: # $ X : int 1 2 3 4 5 6 7 8 9 10 ... # $ 번호 : int 1 2 3 4 5 6 7 8 9 10 ... # $ 계정이름: chr "ahkorea" "parkkeewoo" "zndvn33" "hong_jihee77" ... # $ 작성일 : chr "11/2/2011" "12/30/2011" "1/5/2012" "1/23/2012" ... # $ 내용 : chr # 컬럼명 수정하기 library(dplyr) twitter <- rename( twitter, no = 번호, id = 계정이름, date = 작성일, tw = 내용 ) str(twitter) # 'data.frame': 3743 obs. of 5 variables: # $ X : int 1 2 3 4 5 6 7 8 9 10 ... # $ no : int 1 2 3 4 5 6 7 8 9 10 ... # $ id : chr "ahkorea" "parkkeewoo" "zndvn33" "hong_jihee77" ... # $ date: chr "11/2/2011" "12/30/2011" "1/5/2012" "1/23/2012" ... # $ tw : chr # 특수 문자 제거 twitter$tw <- str_replace_all(twitter$tw, "\\W"," ") head(twitter$tw) # 명사 테이블 만들기 #명사리스트 nouns <- extractNoun(twitter$tw) # 리스트풀어서 테이블로 wordcount <- table(unlist(nouns)) # 데이터 프레임 전환 df_word <- as.data.frame(wordcount,stringsAsFactors = F) head(df_word) # Var1 Freq # 1 ^ㄲ 1 # 2 ^ㄹ 1 # 3 ^ㅈ^ㄹ 4 # 4 ^ㅈ^ㄹ해도 1 # 5 ^ㅋ 16 # 6 ^ㅋ^ㅋ^ㅋ 4 # 변수명(컬럼명) 바꾸기 df_word <- rename(df_word, word=Var1, freq=Freq) head(df_word) # word freq # 1 ^ㄲ 1 # 2 ^ㄹ 1 # 3 ^ㅈ^ㄹ 4 # 4 ^ㅈ^ㄹ해도 1 # 5 ^ㅋ 16 # 6 ^ㅋ^ㅋ^ㅋ 4 #두글자 이상만 추출 df_word <- filter(df_word, nchar(word) >= 2) head(df_word) # 빈도수 높은것 상위 100개만 top100 <- df_word %>% arrange(desc(freq)) %>% head(100) # word freq # 1 종북 2431 # 2 북한 2216 # 3 세력 1162 # 4 좌파 829 # 5 대한민국 804 top10 <- df_word %>% arrange(desc(freq)) %>% head(10) #시각화 library(ggplot2) ggplot(data=top10, aes(x=reorder(word,-freq), y=freq, fill=reorder(word,-freq)))+ geom_col() + ylim(0,2500) # y축 범위설정 ggplot(data=top10, aes(x=reorder(word,-freq), y=freq, fill=reorder(word,-freq)))+ geom_col() +coord_flip() + geom_text(aes(label=freq), hjust=-0.5) ### 클라우드 library(wordcloud) library(RColorBrewer) pal <- brewer.pal(8,"Dark2") # Dark2라는 색상표에서 8가지 색을 추출 set.seed(1234) # 처름 시작값을 주어 매번 같은 값이 나온게 만드는것 wordcloud(word=df_word$word, # 단어 freq=df_word$freq, # 빈도 min.freq = 2, # 최소빈도 max.words =50, # 사용할 단어갯수 random.order= F, # 무작위 배치 F rot.per = .1, # 회전비율 0.1 scale = c(2,0.5), # 단어크기 범위 colors = pal ) pal <- brewer.pal(8,"Purples")[5:9] # Dark2라는 색상표에서 8가지 색을 추출 set.seed(1234) # 처름 시작값을 주어 매번 같은 값이 나온게 만드는것 wordcloud(word=df_word$word, # 단어 freq=df_word$freq, # 빈도 min.freq = 2, # 최소빈도 max.words =50, # 사용할 단어갯수 random.order= F, # 무작위 배치 F rot.per = .1, # 회전비율 0.1 scale = c(2,0.5), # 단어크기 범위 colors = pal )
################## 지도 시각화 하기 # 미국 주별 강력 범죄율 단계 구분도 만들기 install.packages("ggiraphExtra") library(ggiraphExtra) # USArrests 데이터가 포함 head(USArrests) # Murder Assault UrbanPop Rape # Alabama 13.2 236 58 21.2 # Alaska 10.0 263 48 44.5 # Arizona 8.1 294 80 31.0 # Arkansas 8.8 190 50 19.5 # California 9.0 276 91 40.6 # Colorado 7.9 204 78 38.7 # 주이름에 컬럼명이 없다 : 컬럼명에 대소문자가 섞여있다. str(USArrests) # 데이터속성 확인 # 'data.frame': 50 obs. of 4 variables: # $ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ... # $ Assault : int 236 263 294 190 276 204 110 238 335 211 ... # $ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ... # $ Rape : num # tibble : dataframe을 대신해서 쓸 수 있다. simple하다 # 대용량 데이터를 간단하게 다룰 수 있다. # 데이터를 간략하게 표현할 수 있다. # data.frame은 문자로 구성된 데이터가 factor로 인식되는 경우가 종종있다 # tibble은 입력 유형이 변경되지 않는다. library(tibble) # 주 state 컬럼 추가하자 crime <- rownames_to_column(USArrests,var = "state") head(crime) # state Murder Assault UrbanPop Rape # 1 Alabama 13.2 236 58 21.2 # 2 Alaska 10.0 263 48 44.5 # state컬럼 값 소문자로 바꾸기 crime$state <- tolower(crime$state) crime <- rename() # 컬럼명 소문자로 바꾸기 colnames(crime) <- tolower(colnames(crime)) library(ggplot2) # 지도데이터로 바꾸어줌 stats_map <- map_data("state") str(stats_map) # data.frame': 15537 obs. of 6 variables: # $ long : num 경도 # $ lat : num 위도 # $ group : num 1 1 1 1 1 1 1 1 1 1 ... # $ order : int 1 2 3 4 5 6 7 8 9 10 ... # $ region : chr "alabama" "alabama" "alabama" "alabama" ... # $ subregion: chr # 지도 시각화 ggChoropleth() ggChoropleth(data=crime, #지도에 표시할데이터 aes(fill=murder, #색상구분 map_id=state), # 지역기준 map=stats_map) #지도데이터 # 인터렉티브 (반응형) 지도 시각화 ggChoropleth(data=crime, #지도에 표시할데이터 aes(fill=murder, #색상구분 map_id=state), # 지역기준 map=stats_map, # 지도데이터 interactive = T) #반응형으로만들기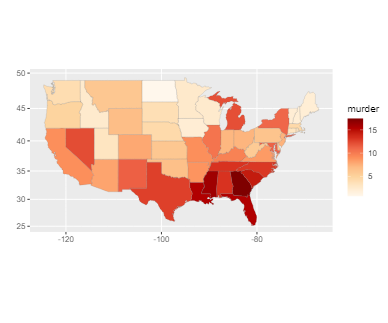
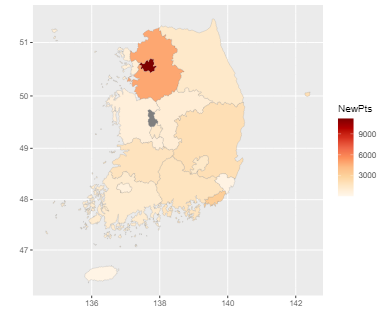
#### 한국 : 시도별 인구대비 결핵확자수 # 단계 구분도 만들기 library(stringi) library(devtools) # 지도 데이터 로드하기 devtools::install_github("cardiomoon/kormaps2014") #github에서 지도가져옴 # 안먹을경우 하둡수업 시 설정했던 유닉스명령어 환경변수 제거 library(kormaps2014) str(changeCode(korpop1)) # 데이터 형 확인 head(korpop1) library(dplyr) # 컬럼명 변경 korpop1 <- rename(korpop1, pop = '총인구_명', name = '행정구역별_읍면동') library(ggiraphExtra) library(ggplot2) korpop1$name <- iconv(korpop1 $name, "UTF-8", "CP949") #인코딩 ggChoropleth(data=korpop1, #자료 데이터 aes(fill=pop, # 색으로 표현할 변수 map_id=code, # 지역 기준 변수 tooltip=name), # 지도 위에 표시할 지역병 map=kormap1, # 지도 데이터 interactive = T) ########### 결핵환자수 newPts str(changeCode(tbc)) head(tbc) tbc$name1 <- iconv(tbc$name1, "UTF-8", "CP949") #인코딩 tbc$name <- iconv(tbc$name, "UTF-8", "CP949") #인코딩 ggChoropleth(data=tbc, #자료 데이터 aes(fill=NewPts, # 색으로 표현할 변수 map_id=code, # 지역 기준 변수 tooltip=name1), # 지도 위에 표시할 지역병 map=kormap1, # 지도 데이터 interactive = T)
### plotly 패키지를 이용한 인터렉티브 그래프 만들기 install.packages("plotly") library(plotly) library(ggplot2) head(mpg) # 반응이 없는 단순 그래프 pt <- ggplot(data=mpg, aes(x=displ, y=hwy, col=drv))+ # 배기량,고속도로연비,드라이브 geom_point() # 변수 간 관계 # 반응형 그래프 ggplotly(pt) head(diamonds) pt2 <- ggplot(data=diamonds, aes(x=cut, fill=clarity))+ geom_bar(position = "dodge") ggplotly(pt2) ################ dygraphs 패키지를 이용한 인터랙티브 시계열 그래프 install.packages("dygraphs") library(dygraphs) economics <- ggplot2::economics head(economics) # date pce pop psavert uempmed unemploy # <date> <dbl> <dbl> <dbl> <dbl> <dbl> # 1 1967-07-01 507. 198712 12.6 4.5 2944 # 2 1967-08-01 510. 198911 12.6 4.7 2945 # 3 1967-09-01 516. 199113 11.9 4.6 2958 # 4 1967-10-01 512. 199311 12.9 4.9 3143 # 5 1967-11-01 517. 199498 12.8 4.7 3066 library(xts) eco<-xts(economics$unemploy, order.by = economics$date) head(eco) # 그래프 생성 dygraph(eco) # 날자 범위 선택 기능 # 하단에 생김 dygraph(eco) %>% dyRangeSelector() # 개인저축률 eco_a <- xts(economics$psavert, order.by = economics$date) # 실업자 수 eco_b <- xts(economics$unemploy/1000, order.by = economics$date) # 1000으로 나누는 이유는 저축률과 함께 쓰기위해 차이가 너무크기 # 때문이다 # 시간변화에 다른 저축률과 실업자수의 변화를 모두 그래프로 그리시오 eco2 <- cbind(eco_a, eco_b) #데이터결합 colnames(eco2) <-c("psavert","unemploy") #변수명 바꾸기 head(eco2) dygraph(eco2) %>% dyRangeSelector()
#### 통계분석기법을 이용한 가설검정 #### # 통계 분석 : 기술통계 - 데이터를 요약해 설명하는 통계 # 추론통계 - 어떤값이 발생할 확률을 계산하는 통계 기법 # # 유의하다 - 어떤일이 발생할 확률이 작다 # 유의하지않다 - 어떤일이 발생할 확률이다. # # 유의 확률 : 실제로는 집단간의 차이가 없는데 우연한 차이가 있는 # 데이타가 발생할 확률 # # 유의 확률이 크다 : 집단간의 차이가 유의 하지 않다 # (집단간의 차이가 어떤일이 발생할확률이 있다) # 유의 확률이 작다 : 집단간의 차이가 유의하다 # (집단간의 차이가 어떤일이 발생할 확률이 작다) ############################# t 검정 - 두 집단의 평균의 비교 mpg <- as.data.frame(ggplot2::mpg) library(dplyr) mpg_diff <- mpg %>% select(class,cty) %>% # 기종과 도시연비 filter(class %in% c("compact","suv")) head(mpg_diff) # class cty # 1 compact 18 # 2 compact 21 # 3 compact 20 # 4 compact 21 # 5 compact 16 # 6 compact 18 table(mpg_diff) # cty # class 9 11 12 13 14 15 16 17 18 19 20 21 22 24 26 28 33 # compact 0 0 0 0 0 2 3 4 7 5 5 12 3 2 2 1 1 # suv 2 13 6 13 12 7 2 1 3 1 2 0 0 0 0 0 0 t.test(data=mpg_diff, cty ~ class, var.equal= T) # Two Sample t-test # # data: cty by class # t = 11.917, df = 107, p-value < 2.2e-16 # alternative hypothesis: true difference in means between group compact # and group suv is not equal to 0 95 percent confidence interval: # 5.525180 7.730139 # sample estimates: # mean in group compact mean in group suv # 20.12766 13.50000 # p-value < 2.2e-16 = 2.2 * 10^(-16) = 0.0000000???22 # 유의확률 2.2e-16e x 100 # 판단 : 5% 보다 적으면 유의하다. 5%보다 크면 유의하지않다 # 결론 : compact, suv 분석은 유의하다. 분석할만한 가치가 있다. ### mpg 데이터의 도시 연비 cty 와 연료fl(레귤러r,프리미엄f)간에 t검정을 해보시오 table(mpg$fl) table(mpg$cty) cty_fl <-mpg %>% select(cty,fl) %>% filter(fl %in% c("r","p")) table(cty_fl) t.test(data=cty_fl, cty ~ fl , var.equal=T) # Two Sample t-test # # data: cty by fl # t = 1.0662, df = 218, p-value = 0.2875 # alternative hypothesis: true difference in means between group p and group r is not equal to 0 # 95 percent confidence interval: # -0.5322946 1.7868733 # sample estimates: # mean in group p mean in group r # 17.36538 16.73810 #p-value = 0.2875 이므로 유의확률은 약28%이다 #r와p의 도시연비 분석은 유의하지않다 ##################################상관관계 분석하기 # 연속되는 두 변수가 어떤 관계인지 검정하는 통계분석 # 관계 : 도시연비와 연료와의 관계 # 정비례, 반비례 등으로 나타난다 # economics에서 실업자수와 개인소비 지출간의 관계를 검정하시오 economics <- as.data.frame(ggplot2::economics) cor.test(economics$unemploy, economics$pce) # Pearson's product-moment correlation # # data: economics$unemploy and economics$pce # t = 18.63, df = 572, p-value < 2.2e-16 # alternative hypothesis: true correlation is not equal to 0 # 95 percent confidence interval: # 0.5608868 0.6630124 # sample estimates: # cor # 0.6145176 # p-value 5% 미만이므로 유의하다 # cor 상관관계 # 0.6145176 값이 양수 이므로 정비례관계이다 ########### 상관관계 히트맵(데이터셋내의 모든컬럼의 상관관계) ########### 만들기 head(mtcars) # mpg cyl disp hp drat wt qsec vs am gear # Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 # Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 # Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 # Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 # Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 # Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 # carb # Mazda RX4 4 # Mazda RX4 Wag 4 # Datsun 710 1 # Hornet 4 Drive 1 # Hornet Sportabout 2 # Valiant 1 # 1) 상관행렬 생성 car_cor <- cor(mtcars) round(car_cor,2) #반올림 소수점 2자리까지 install.packages("corrplot") library(corrplot) # 상관관계 히트맵 corrplot(car_cor) # 상관관계 히트맵 - 수치값으로 표현하기 corrplot(car_cor, method = "number") # 모든 컬럼의 상관관계를 알 수 있다. # 세줄 정리 # 1. t.test : t검정 두집단의 차이를 비교하는것이 의미가있는가 # 2. cor.test : 상관관계 - 연속되는 두데이터의 관계 - 정,반 비례.. # 3. hit map : 데이터셋내의 모든 컬럼 들의 상호 상관관계

마크다운 쓰는법
--- output: html_document: default word_document: default --- # 레포트 만들기 ## 분석 보고서 ### 아래와 같이 cars 데이터셋의 summary 요약을 합니다. ```{r} summary(cars) ``` ### mpg 데이터의 drv별 빈도를 측정해보자 샵없이 글씨 *기울임* **강조** ~~취소선~~ ```{r} library(ggplot2) qplot(data=mpg, x=drv, fill=drv) ```'BigData' 카테고리의 다른 글
210806_1(머신러닝) (0) 2021.08.06 210805_1(머신러닝) (0) 2021.08.05 210803_1(데이터분석, R, 자연어처리/텍스트마이닝) (0) 2021.08.03 210802_1(데이터분석,R) (0) 2021.08.02 210729_1(데이터분석, R) (0) 2021.07.29